
The Importance of Web Archives in Preserving Digital History
In today’s digital age, the internet plays a crucial role in shaping our society and culture. As websites evolve and content changes rapidly, preserving this dynamic digital landscape becomes increasingly important. This is where web archives come into play.
A web archive is a collection of archived web pages that have been saved at different points in time. These archives serve as a historical record of the internet, capturing the evolution of websites, online content, and digital culture over time.
Web archives are essential for various reasons. They provide researchers, historians, and the general public with valuable insights into how websites have changed over time, documenting shifts in design trends, content strategies, and user experiences. They also serve as a crucial resource for preserving cultural heritage, ensuring that important online content is not lost to time.
Moreover, web archives play a vital role in safeguarding against link rot and content loss. As websites are constantly updated or taken down, valuable information can be lost forever. Web archives help mitigate this risk by capturing and preserving web pages for future reference.
One of the most well-known web archives is the Wayback Machine by the Internet Archive. This massive archive contains billions of web pages dating back to the early days of the internet. Users can access snapshots of websites from different points in time, allowing them to see how their favorite sites have evolved over the years.
As we continue to rely on the internet for information and communication, the importance of web archives in preserving our digital history cannot be overstated. By capturing and archiving web pages, we ensure that future generations will have access to a rich historical record of our online world.
Exploring the Past of the Internet: A Guide to Web Archives and Their Significance
- What is a web archive?
- How are web archives created?
- Why are web archives important?
- What is the Internet Archive’s Wayback Machine?
- How can I access web archives?
- Are all websites archived in web archives?
- Can I contribute to a web archive?
- How far back do web archives go?
What is a web archive?
A web archive is a curated collection of archived web pages that have been saved at various points in time. It serves as a historical repository of internet content, capturing the evolution of websites, online information, and digital culture over time. By preserving snapshots of web pages, a web archive provides valuable insights into how websites have changed, documenting shifts in design, content, and user experience. Web archives are essential for researchers, historians, and the general public to explore and understand the dynamic nature of the internet and ensure that important online content is not lost to time.
How are web archives created?
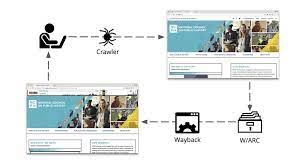
Web archives are created through a process known as web crawling or web scraping. Specialized software, often referred to as web crawlers or spiders, systematically browse the internet and download web pages, storing them in a structured manner for future access. These web crawlers follow hyperlinks on websites to discover new pages to archive, ensuring a comprehensive snapshot of the web at a given time. Metadata such as URL, timestamp, and content information is typically captured during the archiving process to provide context and facilitate searchability within the archive. This meticulous process of capturing and preserving web content allows for the creation of valuable historical records that document the evolution of websites and digital content over time.
Why are web archives important?
Web archives are crucial for preserving our digital history and cultural heritage. They serve as a valuable resource for researchers, historians, and the general public by capturing the evolution of websites and online content over time. Web archives help document changes in design trends, content strategies, and user experiences, providing insights into how the internet has transformed. Additionally, web archives play a vital role in preventing link rot and content loss by archiving web pages that may be altered or removed. By maintaining a record of the dynamic digital landscape, web archives ensure that valuable online information is not lost to future generations.
What is the Internet Archive’s Wayback Machine?
The Internet Archive’s Wayback Machine is a digital archive that allows users to access snapshots of web pages as they appeared at different points in time. It serves as a valuable tool for preserving the history of the internet by capturing and storing billions of web pages dating back to the early days of the World Wide Web. Users can enter a URL into the Wayback Machine and view archived versions of websites, providing insights into how they have evolved over time. This popular tool is widely used by researchers, historians, and the general public to explore the changing landscape of the internet and access historical web content that may no longer be available online.
How can I access web archives?
Accessing web archives is a straightforward process that allows users to explore snapshots of websites captured at different points in time. One common method to access web archives is through online platforms like the Wayback Machine by the Internet Archive, where users can enter a website URL and view archived versions of that site from various dates. Additionally, many libraries, universities, and cultural institutions maintain their own web archives, providing researchers and the public with access to curated collections of archived web content. Some organizations also offer APIs or tools for more advanced users to access web archive data programmatically. Overall, accessing web archives offers a fascinating glimpse into the evolution of websites and digital content over time.
Are all websites archived in web archives?
Not all websites are archived in web archives. Web archiving is a complex and ongoing process that involves capturing and preserving web pages at specific points in time. While major websites and popular online platforms are more likely to be archived regularly, smaller or less frequently visited sites may not be captured as frequently or at all. Additionally, websites can employ measures to prevent archiving, such as using robots.txt files to block web crawlers. As a result, the content available in web archives represents a sample of the vast and ever-changing landscape of the internet, rather than a comprehensive archive of all websites.
Can I contribute to a web archive?
Many web archives welcome contributions from individuals who wish to preserve valuable online content for future generations. By allowing users to contribute to a web archive, these platforms can expand their collections and ensure the preservation of a diverse range of digital materials. Whether it’s archiving a personal website, submitting historical web documents, or recommending important online resources, contributing to a web archive can be a meaningful way for individuals to actively participate in the preservation of our digital history.
How far back do web archives go?
Web archives typically go back to the early days of the internet, with some of the most comprehensive archives dating back to the late 1990s. The Wayback Machine, for example, contains billions of web pages archived since 1996. While the depth and coverage of web archives may vary depending on the specific archive and its collection practices, users can often explore snapshots of websites and online content from different points in time, providing a valuable historical record of the evolution of the digital landscape.